For a quite a while, I have wanted to try and create simple touch based interface for a 2D spaceship game. I want to allow the player to simply drag anywhere on the screen, and the spaceship moves to that position and direction in an efficient manner. Ideally the most efficient manner.
Spaceships in 2D games usually have one main engine that allows forward thrust, and some that allow rotation around the ships center of mass.
Moving from point A to B efficiently (in minimal time) is not trivial with such constraints, as changes to direction and thrust may have huge consequences for later possible movements due to inertia.
So instead of looking at the full A to B problem immediately, I wanted to look at something simpler first, namely to go from having velocity \(v_0\) and pointing in direction \(\theta_0\) to have 0 velocity as fast as possible.
The idea I use originally came from talking to a colleague, but something very similar sounding is mentioned in planning algorithms, though examples always seems to involve driftless systems. Anyway, my current approach involves these known quantities and assumptions:
- \(a\) – Acceleration – The ship can only accelerate by a constant amount, and acceleration turns on and off instantly.
- \(s\) – Turn speed – rotating the ship requires no acceleration, and the ship has constant rotation rate.
- \(\theta_0\) – Initial orientation.
- \(v_0\) – Initial velocity
These quantities allow me to find a legal, but very suboptimal way to stop. It simply involves to turn the ship to face its velocity vector, and then accelerate until it stops. Both the time needed to turn the ship \(t_a\) and the time \(t_m\) needed to turn and reverse the velocity are easy to calculate.
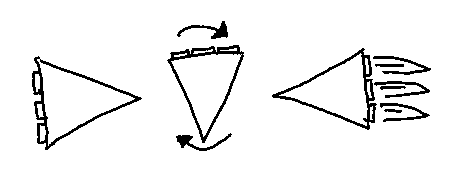
It is also easy to see that this is suboptimal, it would clearly be faster, to start burning some time before the turn is fully completed, but the question is when to start the burn.
To allow for this freedom in my model, I therefore introduce a third time variable \(t_s\). \(t_s\) is the time to start turning and accelerating at the same time. \(t_a\) now becomes the time when I stop turning and only accelerate.
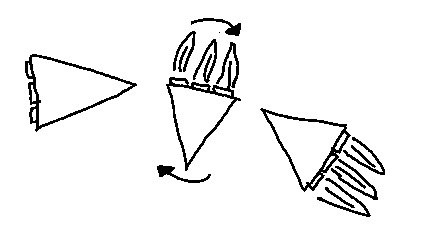
Given these intervals, two integrals describe how the velocity will change when \(t_s\), \(t_a\) and \(t_m\) vary.
$$ v_x = \int_{t_s}^{t_a} a\cos(\theta_0+st)dt + \int_{t_a}^{t_m} a\cos(\theta_0+st_a)dt $$
$$ v_y = \int_{t_s}^{t_a} a\sin(\theta_0+st)dt + \int_{t_a}^{t_m} a\sin(\theta_0+st_a)dt $$
This gives two constraints, that must hold for all solutions of this kind.
$$ 0 = v_{0x} + \int_{t_s}^{t_a} a\cos(\theta_0+st)dt + \int_{t_a}^{t_m} a\cos(\theta_0+st_a)dt $$
$$ 0 = v_{0y} + \int_{t_s}^{t_a} a\sin(\theta_0+st)dt + \int_{t_a}^{t_m} a\sin(\theta_0+st_a)dt $$
The most efficient solution to this problem, is the \(t_s\), \(t_a\) and \(t_m\) triplet with the lowest value for \(t_m\).
This information allows me to formulate this as a optimization problem.
Since I want to minimise \(t_m\), the objective function simply becomes \({t_m}^2\).
This is subject to the two equality constraints given.
Since the objective and constraints are non-linear, I plug i into Optizelle which is a framework for solving non-linear optimization problems.
The implementation can be found on github, it uses autograd, to calculate derivatives and hessians. This is an incredible time saver since calculating 9 combinations of partial derivatives would have been a major pain, not to mention having to recalculate them whenever I did something wrong.
Running the program with inputs \(a=2.0\), \(\theta_0=0\), \(v_0=[2,0]\) and \(s=\frac{\pi}{2}\) returns:
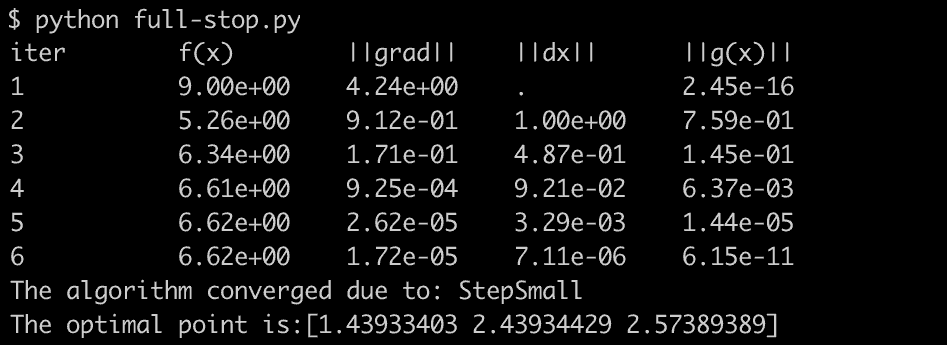
The optimal point vector contains the values for \(t_s\),\(t_a\) and \(t_m\). This means that for a ship with the given input, it should start turning immediately, then start the burn after approximately 1.43 seconds, stop turning and only accelerate at 2.43 and finally be at rest after 2.57 seconds, approximately 0.43 seconds faster then the naive version.
To test the result, I implemented a quick and dirty javascript program that simulates these choices and renders to a canvas:

Sometimes the ships end up drifting a bit after the simulation has finished. This is due to the discrete nature of the simulation not perfectly emulating the continuous solution (I do not integrate rotation analytically in the simulation). This could also have been a problem if I applied this style of planning to a game that did the same, from the simulation above it looks negligible though, which is great!
I am very happy with this result, it seems like it could work for the larger problem as well. The next step I’ll try, is to tackle some specific cases of moving from point A to B efficiently. For those cases there will be many more time variables involved, and possibly many constellations of safe initial starting points as well as possible freedoms to introduce in the model. It will be interesting to see how that works out.
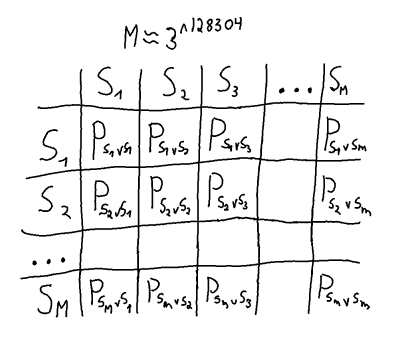
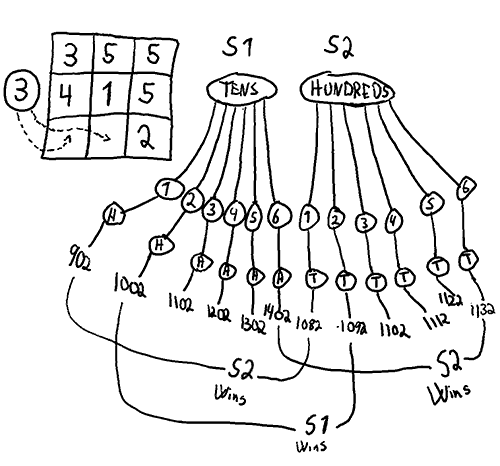
 which given any game state
which given any game state  gives a Get1000 placement
gives a Get1000 placement  . Below is an illustration of what i mean by a state. A state could also include the history (order of placement), which would increase the count a lot, but that is hopefully not needed for a solution.
. Below is an illustration of what i mean by a state. A state could also include the history (order of placement), which would increase the count a lot, but that is hopefully not needed for a solution.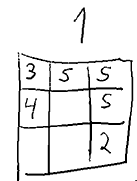
 but in at least
but in at least  the choice is forced. This means there are at most.
the choice is forced. This means there are at most.  relevant states, probably quite a bit fewer.
relevant states, probably quite a bit fewer. unique pure strategies.
unique pure strategies. matrix is enormous, and for each cell in the matrix all possible
matrix is enormous, and for each cell in the matrix all possible  games would have to be played to find the payoff
games would have to be played to find the payoff  for the pure strategy pairs. On top of that, the best mixed strategy would then have to be calculated.
for the pure strategy pairs. On top of that, the best mixed strategy would then have to be calculated.
 denotes time,
denotes time,  the current velocity and
the current velocity and  is the starting position. This restricts the position of the target to a line, where the position on the line is determined by
is the starting position. This restricts the position of the target to a line, where the position on the line is determined by 

 of a constant speed (
of a constant speed ( ) bullet fired from point
) bullet fired from point  in any direction, are given by this equation, where again time is denoted by
in any direction, are given by this equation, where again time is denoted by 

 and
and  from 2 into 4 gives a polynomial that only depends on
from 2 into 4 gives a polynomial that only depends on 

 and
and  and moving towards standard form:
and moving towards standard form:




 coordinates where the torpedo should be aimed, and where it will hit the target.
coordinates where the torpedo should be aimed, and where it will hit the target.


 is the position in the vector, and
is the position in the vector, and  and
and  matrix columns and rows. This also conveniently reduces to bit shifts and masking if
matrix columns and rows. This also conveniently reduces to bit shifts and masking if 

 operations if binary search is used.
operations if binary search is used. can always be divided by the odd component part of
can always be divided by the odd component part of  , as well as the even component divided by two.
, as well as the even component divided by two. :
:

 is the squares where 0 is the largest square, and larger
is the squares where 0 is the largest square, and larger  using the linear search method from above), but finding the position of a single element from its position in the vector.
using the linear search method from above), but finding the position of a single element from its position in the vector.